最近在幫忙debug看到一段有意思的程式碼
我把出問題程式核心概念抽出來碼簡化改寫如下
//common.h
#pragma once
class C1
{
public:
virtual ~C1()
{
}
};
//class2.h
#pragma once
#include "common.h"
#include <memory>
class Class2C1 : public C1
{
};
class Class2
{
std::shared_ptr<Class2C1> p;
public:
Class2();
void run();
};
//class2.cpp
#include "class2.h"
#include <iostream>
class ClassC2 : public Class2C1
{
public:
ClassC2()
{
std::cout << "class2" << std::endl;
}
};
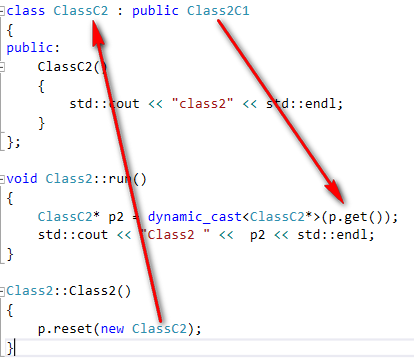
void Class2::run()
{
ClassC2* p2 = dynamic_cast<ClassC2*>(p.get());
std::cout << "Class2 " << p2 << std::endl;
}
Class2::Class2()
{
p.reset(new ClassC2);
}
//class1.h
#pragma once
#include "common.h"
#include <memory>
class Class1C1 : public C1
{
};
class Class1
{
std::shared_ptr<Class1C1> p;
public:
Class1();
void run();
};
//class1.cpp
class ClassC2 : public Class1C1
{
public:
ClassC2()
{
std::cout << "class1" << std::endl;
}
};
Class1::Class1()
{
p.reset(new ClassC2);
}
void Class1::run()
{
Class1C1* pp = p.get();
ClassC2* p2 = dynamic_cast<ClassC2*>(pp);
std::cout << "Class1 " << p2 << std::endl;
}
//main.cpp
#include "class1.h"
#include "class2.h"
int main()
{
Class1* p1 = new Class1;
Class2* p2 = new Class2;
p1->run();
p2->run();
return 0;
}
以上程式碼在VC++2015環境下執行
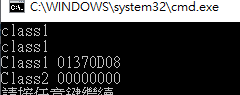
class2.cpp dynamic_cast fail! 如果單純只看class2.cpp
ClassC2* p2 = dynamic_cast(p.get()); std::cout << "Class2 " << p2 << std::endl;
看起來沒有什麼問題,shared_ptr<Class2C1> p 被assign new ClassC2 , 再取出來做dynamic_cast轉回ClassC2
dynamic_cast失敗所以return nullptr,但是shared_ptr p 裡頭存的不是ClassC2 pointer嗎? 應該要能夠down cast成功
如果仔細看,會發現ClassC2同時在class1.cpp, class2.cpp被定義了! 為什麼compile時沒報任何錯呢? 例如redefinition,原因是compile是針對translation unit,在同一個translation unit不能有重複定義,但是在不同的translation unit,標準允許可以重複定義(class type)
以下節錄 C++03 3.2 One definition rule
3.2.1 No translation unit shall contain more than one definition of any variable, function, class type, enumeration type or template. <– 這個是針對同一個translation unit
3.2.5 There can be more than one definition of a class type, enumeration type, … in a program provided that each definition appears in a different translation unit, and provided the definitions satisfy the following requirements — each definition of D shall consist of the same sequence of tokens; and …
重複定義在不同的translation unit是有限制的,例如允許class type、enumeration type。但是function呢? 在C++03 標準中的3.2.3 就有明確提到non-inline function只能存在一份定義在entire program
順帶一提, 一般來說declaration is definition,除了一些例外情況(在C++03 3.1.2 有明確提到 A declaration is a definition unless …),有關class definition 的sample 可參考C++03標準 3.1.3的範例
struct S { int a; int b; }; // defines S, S::a, and S::b
struct X { // defines X
int x; // defines nonstatic data member x
static int y; // declares static data member y
X(): x(0) { } // defines a constructor of X
};
可以看到上面範例struct S,定義了 class type,struct X也定義了 class type(雖然有static member 是declare),因此平常我們在header file寫的class 其實是 「定義」,也就是cpp在include header file時,會存在多份class type定義在不同的translation unit,但標準有提到只要 same sequence of tokens就沒有問題
那平常我們寫class時,不是還會分class.h和 class.cpp嗎?
這邊需區分class definition和member function declaration的概念,可參考C++03標準 9.3 Member functions的部分,9.3.2 A member function may be defined (8.4) in its class definition, in which case it is an inline member function (7.1.2), or it may be defined outside of its class definition if it has already been declared but not defined in its class definition
簡單說 member function是否inline 不影響class的定義
再回到原來的問題,範例程式碼中在class1.cpp class2.cpp都定義了ClassC2 但是內容卻不同,按照標準,這會導致undefined behavior
可是如果只看class2.cpp,在class2.cpp new ClassC2 再dynamic_cast 看到的應該同樣ClassC2才對,也就是class2.cpp內定義的ClassC2才對? 但是dynamic_cast回傳nullptr,顯然代表轉型失敗了,也就是runtime RTTI判斷並非同一個繼承樹
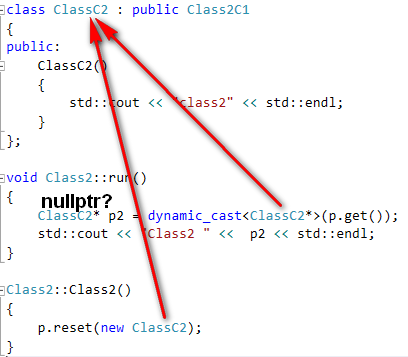
事實上如果看construtor的內容 class2.cpp new ClassC2是call class1.cpp的實作,因此推測dynamic_cast比對到不同版本的ClassC2 (同樣的code在g++ 不是nullptr,這部分跟實現有關)
再追下去,看class2.cpp assembly
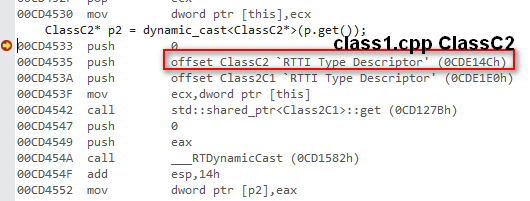
__RTDynamicCast : https://docs.microsoft.com/en-us/cpp/c-runtime-library/rtdynamiccast?view=msvc-140
我們可以看到SrcType是Class2C1, TargetType是ClassC2 (但這個ClassC2是class11.cpp定義的)
__RTDynamicCast 的實作可以在C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\crt\src\vcruntime\rtti.cpp 看到,這邊會轉失敗的原因應該是在__RTDynamicCast裡走到FindSITargetTypeInstance 會再比對SrcType和TargetType的關係導致return nullptr (這一段是直接從source code推敲的,實際情況還需要另外debug trace)
在不同cpp中出現相同的class name看起來是很誇張的錯誤,但是其實不是不可能發生,例如在一個project中不同的開發者分別在不同的cpp中想到相同的名稱,也有可能是剪剪貼貼忘記改掉名稱,這些一旦出現問題時常常很難debug,特別是dynamic_cast是runtime的行為,例如在command pattern,從command queue取出來的command在一般會做down cast轉型,在這種情況下,不一定每次都會轉到有問題的command type
當然,一旦轉錯時,就會出現nullptr,如果又沒有特別檢查可能就會object call method時 nullptr access而crash,或是被nullptr check默默地屏蔽掉,又增加debug的困難度,但總結來說,dynamic_cast fail就是在型別轉換上失敗,有可能是不在同一個繼承樹,也有可能是同一顆繼承樹,但是private 繼承等原因,這個就需要根據實際情況推敲判斷了
像上面提到class definition多分的問題,因為是各自不會互相使用到,除了可以將class name改掉,另外一種做法是用unamed namespace
namespace的機制對於多人共同開發的project非常有用,避免重複名稱可以利用類似Java的做法,限定namespace + directory structure + class對應檔案名稱來解決,即便是想到相同的class name,但是因為在不同namespace,所以不會違反one definition rule,而如果在相同的namespace想到相同的名稱,那代表會存在相同的cpp路徑,在多人合作時,就會發現衝突
而如果是限制在單一個內部使用,建議可以使用file scope的作法 – unamed namespace,避免內部使用的名稱被外部(linker)看到